Spark-da niyə RDD-dən DataFrame-ə keçdik?
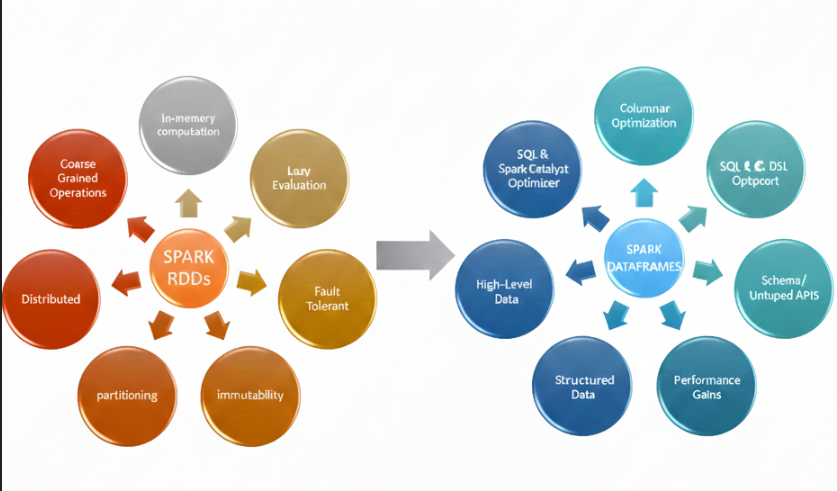
Spark 1.0-da əsas abstraksiya RDD (Resilient Distributed Dataset) idi.
Paylanmış və dəyişdirilə bilməyən obyektlər üzərində işləməyə imkan verirdi və uzun müddət Spark-ın əsas hesablama modeli oldu.
Amma problem burda idi.
RDD-lər struktur məlumatın nə olduğunu bilmirdi. Gələn datanın:
- hansı tipdə olduğunu
- hansı sütunun nə ifadə etdiyini
- ümumiyyətlə strukturunu
anlamırdı. Hər bir element sadəcə obyekt idi.
Bu isə optimizasiya problemini yaradırdı. Spark RDD üzərində yazılan kodun nə etdiyini tam anlaya bilmədiyi üçün onu optimaalaşdıra bilmirdi.
Spark 2.0 ilə birlikdə bu yanaşma dəyişdi və DataFrame əsas abstraktsiyalardan birinə çevrildi.
DataFrame-lərin əsas üstünlüyü ondan ibarətdir ki, məlumatın schemasını və struktunu öncədən bilir. Deyək ki DataFrame-i pandas və ya polarsdan import edirik — Spark hər bir sütunun hansı tipə aid oldugunu özü müəyyən edir.
Bu da bizi tip təhlükəsizliyi anlayışına gətirir. Tip təhlükəsizliyi sistemin tipləri öncədən düzgün tanımasıdır və bu, production-da yaranacaq bir çox problemin qarşısını əvvəlcədən alır.
Spark-da hər hansı action çağırdıqda (məsələn write()), arxa planda Catalyist Optimizer və Tungsten işə düşür. Catalyist bütün transformation əməliyyatlarına bir bütün kimi baxır və icra zamanı optimallaşdırmalar tətbiq edir.
Məsələn:
- lazm olmayan sətirlər oxunmur (predicate pushdown)
- transformasiyalar bir fiziki mərhələdə (stage) icra olunur
- diskə yazma/oxuma minimuma endirilir
MapReduce-da hər addım diskə yazılırdı. Spark isə mümkün qədər RAM-da işləyərək gecikməni azladır və performasnsı artırır.
DataFrame və Dataset-in burda ən böyük üstünlüyü xətaları erkən mərhələdə aşkar etməsidir. RDD-də bir sütunda rəqəm olmayan dəyər varsa, problem yalnız runtime-da üzə çıxır və bütün pipeline çökə bilər.
DataFrame və Dataset-in tip təhlükəsizliyi bu cür data keyfiyyəti problemlərini production-dan əvvəl aradan qaldırmağa kömək edir.
Burda bir də UDF (User Defined Function) mövzusu var. UDF-lər Spark-ın native funksiyalarından deyil, Python funksiyalarından istifadə edir və bu performans problemləri yaradır.
UDF istifadə edəndə Spark JVM-dəki hər bir məlumat sətrini Python interpreter-ə göndərmək üçün seriyallaşdırır, nəticəni geri alanda isə yenidən deserialize edir. Bu get-gəl ciddi yüklənmə (overhead) yaradır.
Üstəlik, Catalyist optimizer UDF-ləri optimallaşdıra bilmir, amma native Spark funksiyaları üçün bunu edir.
Ona görə də production pipeline-larda:
- mümkün qədər DataFrame / Dataset API-lərindən
- native Spark funksiyalarından
istifadə etmək daha sağlam yanaşmadır.