Niyə Apache Spark?
Məlumatla işləyərkən işin ilk və ən ağır hissəsi adətən məlumatın ilkin emalıdır.
Təmizləmə, fərqli mənbələrdən gələn dataların birləşdirilməsi və xüsusiyyət mühəndisliyi — yəni ML-ə keçməzdən əvvəl datanı “istifadə edilə bilən” hala salmaq.
Problem burda başlayır.
Analitika və ML pipeline qurarkən eyni əməliyyatları dəfələrlə edirik:
fayl oxuma, join etmə, filter, transformasiya və s.
Pipeline məntiginə görə bu addımlar təkrar-təkrar icra olunur və nəticədə eyni işi dəfələrlə etmiş oluruq. Bu isə prosesi yavaşladır və ciddi optimizasiya problemi yaradır.
Bu nöqtədə adətən laboratoriya mühiti ilə production (Fabric) mühiti arasındakı fərq ortaya çıxır.
Lab mühitində:
- kod işləyir
- analiz aparılır
- hipotezlər test olunur
- vizuallaşdırmalar edilir
amma bu kodların istehsalatda 7/24 işləmək kimi bir öhdəliyi yoxdur.
Fabric (production) mühitində isə tələblər tamam başqadır.
Burda pipeline sadəcə işləməməli, dayanıqlı, genşlənəbilən, idarəoluna bilən olmalıdır. Xətalar minimum insan müdaxiləsi ilə idarə olunmalı, data keyfiyyəti qorunmalıdır.
Əgər biz lab-da Python ilə yazdığımız kodu production üçün təkrar Java və ya Scala ekosisteminə uyğunlaşdırsaydıq:
- əlavə xərc
- əlavə iş yükü
- çox aşagı agility
qaçılmaz olardı.
Məhz burda Apache Spark önə çıxır.
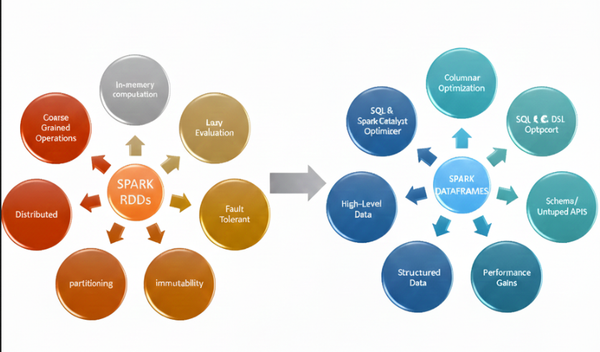
Spark bir neçə maşın üzərində işləyə bilən, ümumi bir çərçivə təqdim edən framework-dü. Alternativləri var (MapReduce kimi), amma Spark-ı fərqli edən əsas məqamlar bunlardır:
- fərqli dillər üçün eyni framework (Scala, Python)
- məlumat analizi üçün daxili optimallaşdırmalar
- datanın diskdə deyil RAM-da işlənməsi
- HDFS, S3 kimi sistemlərlə rahat inteqrasiya
Spark-ın real gücü isə DAG məntigində ortaya çıxır.
MapReduce-da hər əməliyyatdan sonra datanı diskə yazırsan.
10 əməliyyat varsa, 10 dəfə oxu-yaz. Bu prosesə shuffle deyirik və performansı ciddi şəkildə aşağı salır.
Spark-da isə:
- datanı RAM-da saxlayırsan
- transformasiyalar ardıcıl şəkildə icra olunur
- sonda diskə yazılır
DAG scheduler bütün bu mərhələləri sənin yerinə planlayır və sən bu detalların içinə girmirsən.
Bunun üzərinə in-memory cacheing gəlir. Spark dataseti cache-də saxlayaraq pipeline-in növbəti mərhələsində təkrar istifadə etməyə imkan verir. MapReduce-da bu vardı, amma hər Map mərhələsindən sonra diskə yazmaq məcburiyyəti olduğu üçün real fayda vermirdi.
Pipeline hazır olduqdan sonra isə iş bitmir.
“Model işləyirsə, data mühəndisi niyə lazımdır?” sualı burada ortaya çıxır.
Cavab sadədir: production hazırlığı.
Data mühəndisi:
- pipeline mərhələlərini təyin edir
- orchestrasiya qurur
- sistemi reliable şəkildə dizayn edir
- data keyfiyyətini və xəta idarəetməsini təmin edir
- resurs optimizasiyası aparır
- Spark worker-lərin necə işləyəcəyini müəyyən edir
Yəni modelin işləməsi başlanğıcdır.
Əsas məsələ onun real dünyada problemsiz işləməsidir.
Apache Spark bu boşluğu dolduran əsas texnologiyalardan biridir.