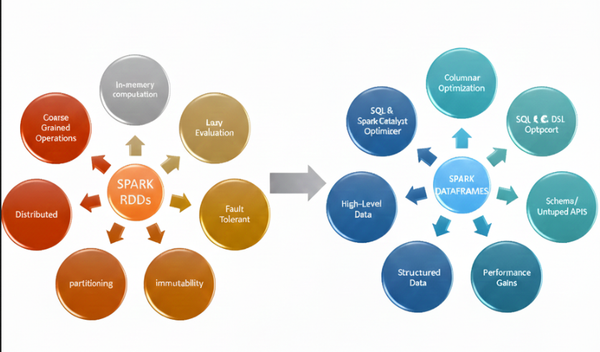
Spark-da niyə RDD-dən DataFrame-ə keçdik?
Spark 1.0-da əsas abstraksiya RDD (Resilient Distributed Dataset) idi. Paylanmış və dəyişdirilə bilməyən obyektlər üzərində işləməyə imkan verirdi və uzun müddət Spark-ın əsas hesablama modeli oldu. Amma problem burda idi. RDD-lər struktur məlumatın nə olduğunu bilmirdi. Gələn datanın: * hansı tipdə olduğunu * hansı sütunun nə ifadə etdiyini * ümumiyyətlə strukturunu anlamırdı.